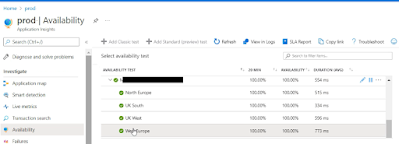
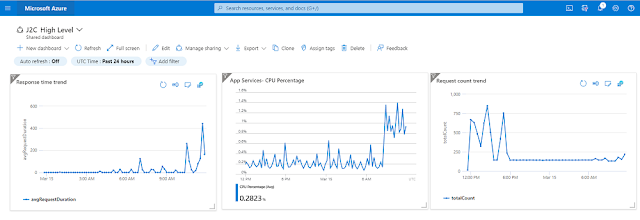
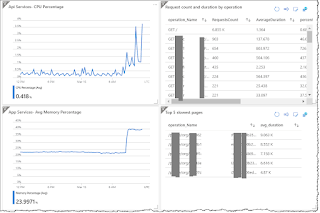
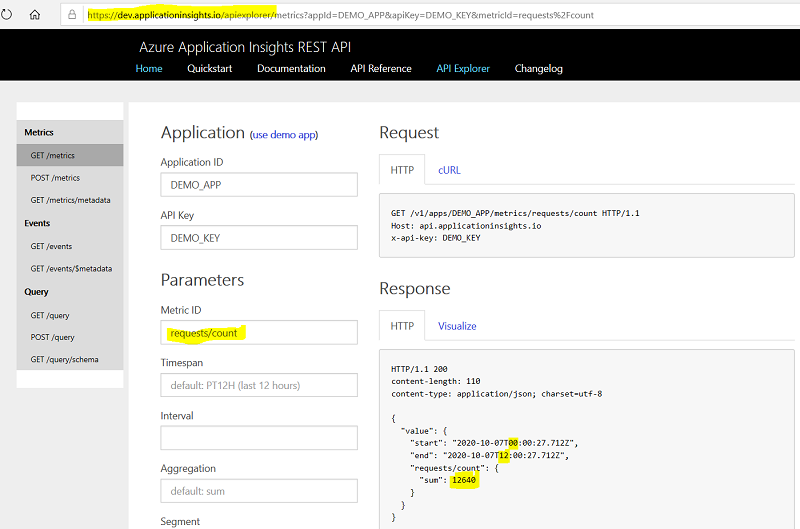
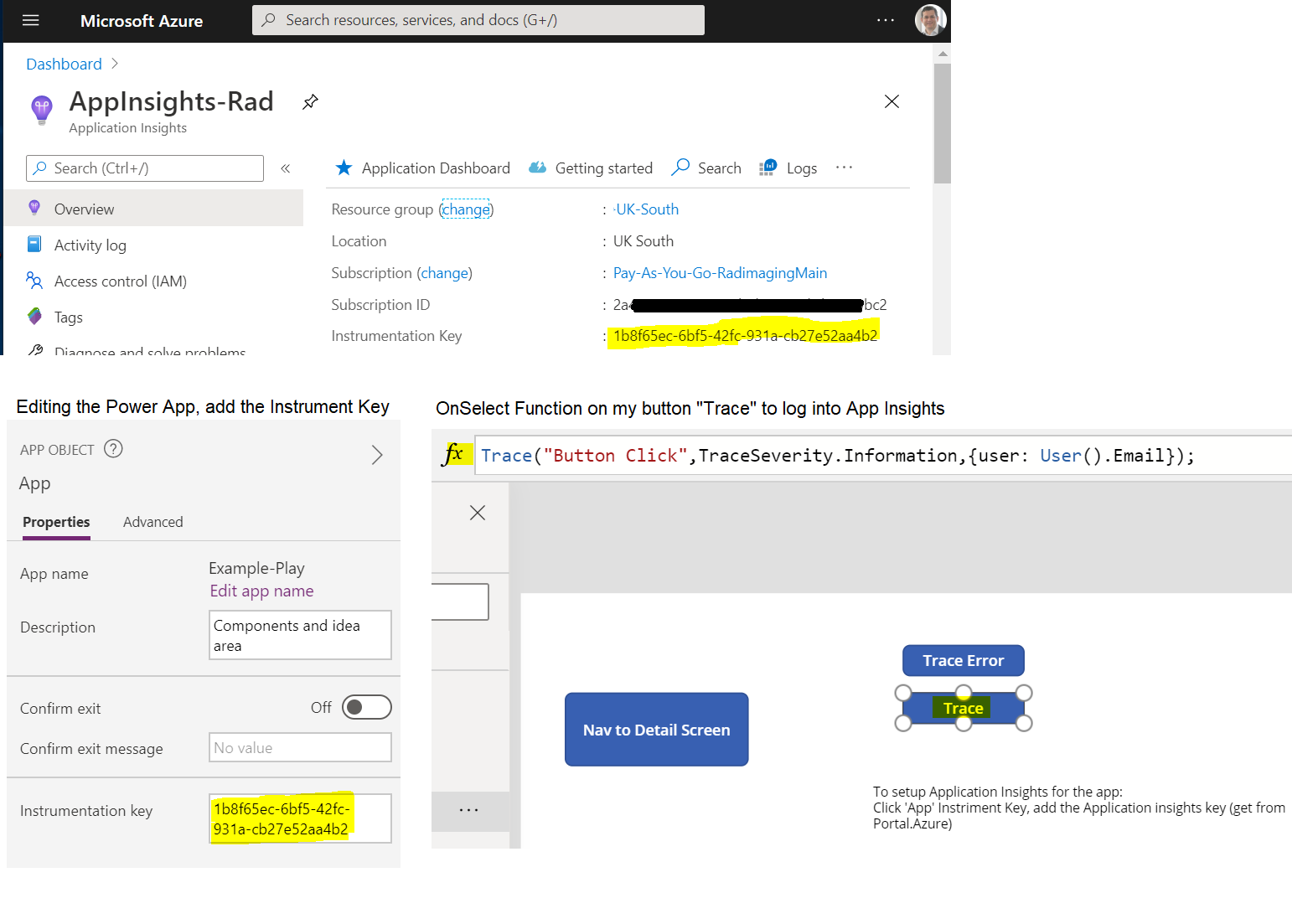
Overview: App Insights provides independent infrastructure for logging and tracing activities. It is tightly coupled with Azure services including PaaS. This allows for consistent scalable logging. App Insights now stores logs in Azure Log Analytics, these are all under the umbrella of Azure Monitor,
On a SaaS solution, I am looking for App Insights to log any errors have the ability to log trace information. I want a unique correlationId (to allow for distributed tracing) on the front end if there is an error so support can identify the exact issue/transactions. A unique correlationId in the http header allows for identifying a transaction and this is useful for tracing and performance monitoring. Using the App Insights SDK's and implementing a common logging module is a good idea. There are two common areas that need call out to ensure the ability to trace transactions:
- SPA's (Requirement to generate a unique operation/correlationId per operation not per pageview), and
- Long running operation such as timer jobs or service bus calls.
Support & DevOps:
Having a correlationId allows first line to log the correlationId and quickly follow the request without asking for replication steps. This context tracing approach is common on newer applications. Third line support has full traceability of an issue to support who can empirically see the perceived performance parts broken down using the correlationId in the header.
Key API's can be continuously monitored for errors and slow down in performance, alerts can be configured around this monitoring.
Building a first line support tool that displays the errors in a hierarchy, has help scripts and knowledge bases is a good option for streamlining support.
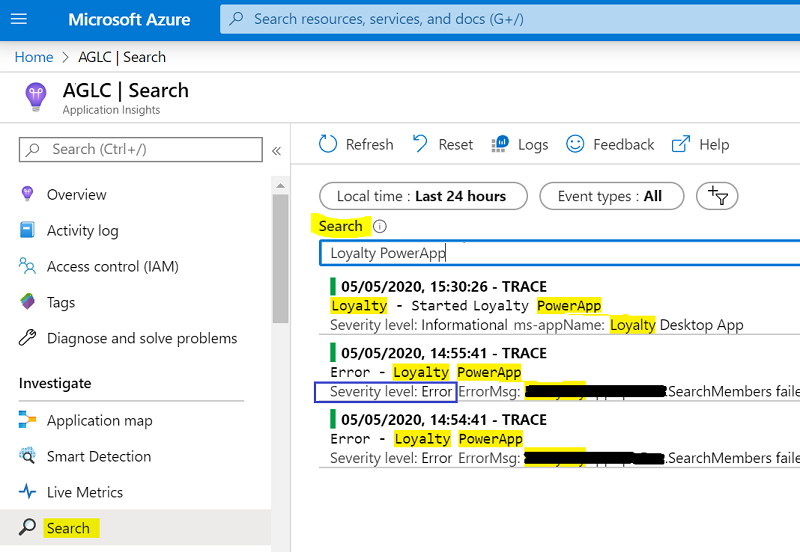
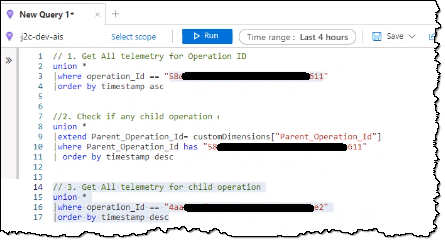
App Insights has live monitoring and also has Kusto query language is useful for monitoring specific queries.

 |
| source cloudiqtech |
Alerting: I all to often see an overuse of alerting resulting in recipients ignoring a plethora of emails. I believe in minimising alerts especially via email, and SMS type messaging. For me, I like to create a dedicate channel for alerting that includes all DevOps members and either notify via a Teams card, and even easier is to email the channel. This can be broken down further but to start I create a channel for alerting for each DTAP environment.
Note: The default channel setup only allows members of the teams channel to send email so the alerts from Azure monitor using rules won't be accepted. On the channel, and admin needs to go to the "advance settings" and change the option from "Only members of this Team" and change it the setting to "Anyone can send".
Options: There are great services for logging so my default tends to be Azure Monitor. The main players in Application & API observability and monitoring include:

- Microsoft: Azure Monitor includes Application Insights & Azure Log Analytics
- Dynatrace (really good if you use multicloud) or Dynatrace AWS cloudwatch, Dynatrace - Saas offering is on AWS. Can be on-prem. OneAgent is deployed on the Compute i.e. VM, Kubernetes. Can import logs from other SIEMs or Azure Monitor, so you can eventually get Azure service logs such as App Service or Service Bus. Does Full stack and includes code-level and applications and infrastructure monitoring, also can show User monitoring. Dynatrace offers scalable API's that are sitting on Kubernetes. "Davis" is the AI engine used to help figure out the problems. Alerting is solid.
 |
| High-level Architecture |
 |
| Dynatrace Admin Monitoring |
- AWS: Amazon CloudWatch Synthetics
- AppDynamics,
- Datadog (excellent),
- New Relic,
- SolarWinds (excellent)
 |
| SolarWinds admin UI from circa 2013/2014 |
 |
| Dynatrace |