
Overview: Buyers, whether B2B or B2C, will likely want to understand your licensing, associated costs, and level of service. Keep it simple, keep it understandable, and make sure you cover what availability, performance, and actions users can use your service for are all clearly outlined in your Service Level Agreement (SLA).
Licensing pricing options: Pay-per-use one-off, yearly, pay-per-user monthly or annual, pay-per-consumption, e.g., Stripe.
SLA:
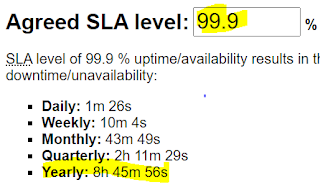
- Availability 99.9 or better is good; it really depends on what you are offering, but there are often penalties for missing availability SLA. If I build a standard SaaS application that utilises App Services, APIM (standard, premium geo-loaded has a higher SLA) and Azure SQL, I can't achieve a 99.9% SLA excluding AAD and any patching or application-caused downtime. At a SaaS product level, providing an actual 99.999% (5 nines) SLA is not as easy as the marketing and legal stakeholders might assume.


- Support - phone, bot, email and max time to respond and time to resolve.
- B2B Monitoring - Good idea to monitor your SaaS provider and not just take their word for it. Technically, monitor the availability of individual services (websites or API's), it is also good to know when items outside of your control (with the SaaS vendor) are unavailable in internal support. Examples include page load times and login times, where you are looking for availability and speed. How much of the service is down, and how much does this affect end customers? You may want to use a 3rd party tool or write your own as a last resort to monitoring. When relying on 3rd parties to provide services, ensure you do a hazard risk assessment. Plan for when things happen, how you will respond, and how you will adjust.
SLA's need to consider both RTO and RPO

Availability = ((Total Minutes−Unplanned Downtime)/Total Minutes) ×100
The formula used to calculate actual availability.
Note: Planned downtime is not typically included in availability calculations, so be aware of what you are in for early.
SLA vs SLO vs SLI:
- SLA (Service Level Agreement - contractual agreement SaaS company makes with the customer.
- SLO (Service Level Objective) - Goal availability (and acceptable performance) of the microservice or application. Measurement goal.
- SLI (Service Level Indicator) - checks if SLO is achieved. Actual Measurement.
As part of High Availability and scalability, it is a good idea to know how many instances and how autogrowth is set up. Here is an example for Azure App Services.

Scale Out (CPU or Memory) - Matrix Threshold (Avg): 70, Duration: 5 Min, Cool down Time: 5 Min, Increase Count: 1
Scale In (CPU or Memory) - Matrix Threshold (Avg): 40, Duration: 30 Min, Cool down Time: 10 Min, Decrease Count: 1
