This post relates to a previous strategy blog post, read that first https://www.pbeck.co.uk/2023/02/setting-up-azure-application-insights.html
Overview: Microsoft uses Azure Application Insights to natively monitor Power Apps using an instrumentation key at the app level. To log for model driven apps and Dataverse this is a Power Platform config at the environment level e.g. UAT, Prod.
When setting up Application Insights, use the Log Analytics workspace approach and not the "Classic" option as this is being deprecated.
Power Apps (Canvas Apps): Always add the instrumentation key to all canvas apps, it is set in the "App" level within each canvas app. Deploy solutions brings challenges with changing keys for app insights logging (unmanaged layers).
"Enable correlation tracing" feature imo. should always be turned on, it is still an experimental feature but with it off, the logging is based on a sessionid
"Pass errors to Azure Application Insights" is also an experimental feature. Consider turning it on.
Canvas Apps have "Monitor", Model driven apps also have this ability to monitor, and Power automate has it's own monitoring
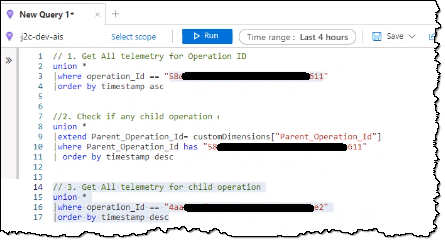
Log to App Insights (put app insights on Azure Log analytics), simple example with customDimensions/record.
Trace("My PB app ... TaxAPI.NinoSearch Error - Search - btnABC", TraceSeverity.Error,// use the appropriate tracing level{ myappName: $"PB App: {gblTheme.AppName}", myappError: FirstError.Message,// optionalmyappEnvironment: gblEnv, myappErrorCode: 10010, myappCorrelationId: GUID()// unique correlationId} );
Query the logs using kusto:traces
| extend errCode = tostring(customDimensions["myappErrorCode"]), err = tostring(customDimensions["myappError"])
| where errCode == "100100"Coming June 2023
Push cloud flow execution data into Application Insights | Microsoft Learn
Allows logging to tie Flows back to the calling Canvas app. You can now do this manually but it has to be applied at all calls to or after the flow.
Below is a basic checklist of decisions to ensure you have suitable logging
Logging Checklist:
- Setup Azure Log Analytics (1 per DTAP env e.g. uat, prd)
- Get the workspace key needed for logging to Log analytics "Agents" > "Log Analytics agent instructions", copy the Workspace Id and the Secondary Key
- Create an Azure Application Insights per DTAP
- Each Canvas app needs an instrumentation key (check, have you aligned DTAP log instances with the Canvas App DTAP)
- Power Automate has great monitoring, but it is a good idea to setup logging for Dataverse (which shall cover model apps), done thru Power Platform Admin Studio > Environment
- Enable Logging Preview Feature for Canvas apps & check the power automate push cloud execution feature state.
- Do you have logging patterns in you Canvas app for errors, do you add tracing, and is it applied consistently?
- Do you have a Pattern for Power Automate runs from Canvas apps? I like to log if the workflow errors after the call.
- Do you have a Pattern for Custom Connectors?
- Do you correlation trace Custom API (internal and 3rd party)?
- Do you have a Try, Catch, Finally scope/pattern for Workflows. How do you write to the logs, most common is to use an Azure Function with the C# SDK. I like to use the Azure Log Analytics Connector in my catch scope to push error info into the workspace log using a custom table.
- Ensure all Azure Services have instrumentation keys. Common examples are Azure Functions, Azure Service Bus, API Manager, the list goes on...
- Do you implement custom APIM monitoring configuration?
- Do you use the SDK in your code (Functions etc.)?
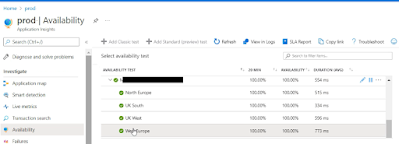
- Setup Availability tests - super useful for 3rd party API's.
Once you have the logs captured and traceable (Monitor & Alerting Checklist):
- Create Queries to help find data
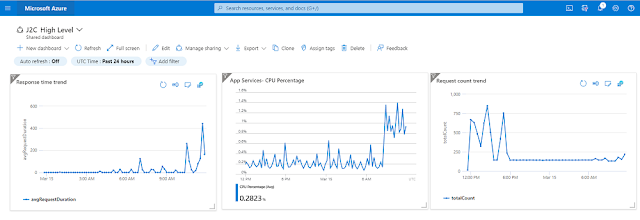
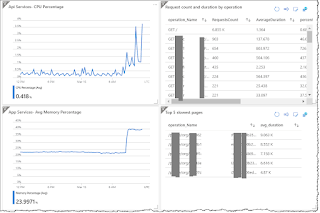
- Create monitoring dashboard using the data
- Use OOTB monitoring for Azure and the platform
- Consider linking/embedding to other monitors i.e. Power Automate, DevOps, Postman Monitor
- Setup alerting within the Azure Log Workspace using groups, don't over email. For information alerts, send to Slack or Teams (very simple to setup a webhook or incoming email on a channel to monitor)
- Power Automate has connectors for adaptive cards channel messaging, consider using directly in Flows or from alerts, push the data into a flow that will log the alert using an adaptive card right into the monitoring channel.